As someone who’s very interested in both travel and tech (check out my travel blog here), I’ve been thinking of how these 2 areas can come together to create cool new ideas. As a first step (coming from a data ‘background’), I wanted to be able to access more travel related data in a less manual data and see what I can come up with from that.
Wikivoyage provide a dump of text from its articles so I thought that would make a good starting point. Looking through the different articles, I was wondering if it would be possible to somehow link them all together by extracting the relationships between them. For example, Singapore is part of Southeast Asia, and so is Malaysia, and Southeast Asia is in turn part of Asia. Mapping out the relationship between all the articles (assuming they are all destinations) would turn the vast number of available destinations into something more structured and navigable.

Turns out, one of the tags in the text dumps, ‘IsPartOf’, contains information about the next level in the hierarchy from that destination article. For example, Singapore would be tagged as part of Southeast Asia, but what is beyond Singapore and what is beyond Southeast Asia is not found in that article. What remains then would be to map all these pairs all the way from end to end.
I’m not too sure if such a ‘map’ is already available but I thought it would make a good Python exercise, given that I’m still learning Python. So here’s what I’ve came up with to create a giant graph of the destinations listed on Wikivoyage. Would be really cool if any part of this turns out to be useful for anyone else! Pretty beginner code, so I’d love for some feedback. All the code for this exercise can be found here.
1. Downloading Latest text dumps from Wikivoyage
In the first cell I initiate some of the libraries that are used throughout the exercise, and download the dump to the working directory. If you’ve already downloaded the dump in that directory the cell with just import the libraries.
import os, urllib, json
from pprint import pprint
url = 'https://dumps.wikimedia.org/enwikivoyage/latest/enwikivoyage-latest-pages-articles.xml.bz2'
if not os.path.isfile(url.split('/')[-1]):
#this step takes some time
urllib.urlretrieve (url, url.split('/')[-1])
Should be straightforward here, and you should now have a new file in the working directory, the text dump ending with .bz2.
2. Decompressing the dump
The data comes in XML, compressed in bz2. So first we’ll decompress the data.
decompressed = ('.').join(url.split('/')[-1].split('.')[:-1])
Creates the file name of the decompressed file, removing ‘.bz2’ from the end of the original file name.
from bz2 import BZ2Decompressor
if not os.path.isfile(decompressed):
with open(decompressed, 'wb') as new_file, open(url.split('/')[-1], 'rb') as file:
decompressor = BZ2Decompressor()
for data in iter(lambda : file.read(100 * 1024), b''):
new_file.write(decompressor.decompress(data))
The decompression step can take some time, and you should end up with another file in the working directory, the decompressed version ending with .xml. It will only occur if you have not already decompressed the file in this directory.
3. Turning XML data to dictionary
Being more familiar with handling dictionaries I took the easy way out and converted the data to a dictionary first before initiating processing. The end goal is to save a JSON file with article name (destinations) as key and the article’s text as the values.
if not os.path.isfile('wikivoyage_latest_articles_text.json'):
import sys
!{sys.executable} -m pip install xmltodict
# https://jakevdp.github.io/blog/2017/12/05/installing-python-packages-from-jupyter/
import xmltodict
#this step takes some time
with open('enwikivoyage-latest-pages-articles.xml') as fd:
doc = xmltodict.parse(fd.read())
data = doc['mediawiki']['page']
print('To process %s records' %len(data))
del doc
This step can also take some time so I’ve made it to run only if the intended output file is not yet available. I don’t think the way I’m installing xmltodict is ideal, still trying to figure it out for iPython notebooks (more used to pipenvs on IDEs, still loads to learn). With that we’re close to touching the actual text! The number of records are the number of articles found.
4. Ignore redirects, get only articles with text
Of these 60,138 records, some are redirects, while some do not contain text. While cleaning these records to obtain their text parts (which contains the tags we’re interested in), we’ll exclude the records which will not provide what we need. To make the output more readable we’ll use the article title as the key, handling the risk that there may be more than 1 with the same title by appending the relevant text into a list belonging to the same title before joining them. I’ve added a counter to keep track of progress.
if not os.path.isfile('wikivoyage_latest_articles_text.json'):
from collections import defaultdict
completed =0
articles = defaultdict(list)
for item in data:
if 'redirect' not in item:
try:
articles[item['title']].append(item['revision']['text']['#text'])
except KeyError:
continue
completed+=1
if completed%10000==0 or completed==len(data):
print('Completed %s' %completed)
print('Found %s articles' %len(articles))
for article, text in articles.iteritems():
articles[article] = "".join(text)
with open('wikivoyage_latest_articles_text.json', 'w') as f:
json.dump(articles, f)
del articles
del data
As the objects can be huge I’ve cleared the variables that won’t be required later on. Finally this output is saved as ‘wikivoyage_latest_articles_text.json’, to be used in our next step, and potentially future projects. From 60,138 records we’ve reduced it to 36,608 records.
5. Extracting parent article, latitude, longitude, and destination category from tags in text
Here’s where it starts to get messy.
Having gone through some samples I’ve found the tags which would provide the information for this purpose. More cleaning is also done to exclude non-destination articles from the output. It was quite a bit of a back and forth process, going through this step, examining the output, then coming back here to clean it further. What’s left is a fairly refined (but quite manual) end result.
Breaking it down:
Skipping non-destinations
The first section starts by skipping articles which are not destinations. Some can be inferred from their names, such as ‘Template’, ‘File’, ‘Category. Others can be inferred from tags found within the text, such as ‘itinerary’, ‘Gallery’, ‘phrasebookguide’. Tags are extracted using the regular expression library (re).
Finding hierarchical relationship tags
The second section extracts the information we’re looking for, which other destinations that currently processed article is a part of. As these tags are manual inputs we can expect inconsistent spellings, eg ‘IsPartOf’ and ‘isPartOf’. Both (different ‘i’s) need to be extracted.
Extracting geo tags
The third part extracts the ‘geo’ tag, which contains latitude and longitude information of that destination.
Extracting destination category tags
The fourth part deals with the destination type. There are tags within articles which provide information on whether that destination is a continent, country, city, region, airport or more, and this part tries to extract as much as possible from the text tags.
Consolidating the data
Next, #5 consolidates the extracted data, processing only those with lat – long information and skipping dive guides (I had trouble using the data for another purpose when I included them). But for your purpose you may want to include those.
To deal with spelling issues (minimising, not eliminating), I lowercase all destination names as well as the parent destination names. In most cases accents can be matched but I found 2 which had consistency issues thus I removed the accents.
Cleaning Lat-long and parent destination name
In cases where more than one geo tag is found, the last one is used, with the first number saved as the latitude and the second, the longitude. These won’t be used in this exercise but probably in future projects.
For the parent tags, some broken tags leave hanging curly brackets, so these are cleaned, along with lowercasing all names and replacing underscores with spaces.
The huge chunk dealing with specific cases and editing the parent name is to handle cases where the tags lead to a dead end due to naming inconsistency or missing links.
Cleaning destination categories
7 different destination types are identified in step 7: airport, city, continent, country, district, park and region. I figure this may come in handy in future.
This dictionary of destination details is then saved to ‘destination_details.json’ for quick retrieval in future. This processing step further cleans the number of usable records to 24,924.
6. Mapping out the entire hierarchy of all available destinations
With the most manual part of this project done, this step is probably the most mind bending – figuring out the rules and logic to join all the available destination-parent pairs up into a huge hierarchy with 24,924 entities.
Breaking it down to the possible scenarios when we encounter each of the pairs:
1. The parent destination already exists somewhere in the current map
In this case we’ll need to be able to locate the position of the parent destination within the existing map and add the child destination as a node under it.
2. The parent destination does not exist in the current map, but the child destination does
Given that we’ve considered case #1 first, case #2 can only happen if the child destination exist as a top level node (thus not having a parent yet). In this case we’ll pop the entire existing child destination node and attach it to a new top level node which is the parent destination.
3. Neither child not parent destination exist in the current map
In this case we’ll just add a new (isolated) key value pair of the parent and child destination to the current map.
In addition, whenever we update the existing map in case #1 or #2, we have to search through the existing nodes to see if any of the branches can be merged. To illustrate:
Before:
{
'A': {'B': {} },
'C': {'D': {} }
}
From article B we identify that B’s parent is A, and from article D we identify that C is D’s parent destination. We do not know of any relationship between B and C.
If we encounter article C which informs us that B is C’s parent, going through the above cases in that order, we first find that B exists in the current map, updating the current map to:
{
'A': {'B': {'C': {}} },
'C': {'D': {} }
}
Then we find that C also exist in the current map as a top level node and pop it out and attach it to C the child node, getting:
{
'A': {'B': {'C': {'D': {} } } },
}
So that’s an illustration of what we’re going to do.
The recursive functions
I used a recursive function that takes in a dictionary (that can be changed) and whether the current step has been mapped, and returns that dictionary (possibly edited) as well as whether the step has been mapped. I’ve kept the child and parent destination names out of the function as these do not change throughout the iteration and can be taken as global variables. Within the function ‘map_destinations’:
Case 1: Finding if the parent exists in the current map as key
if parent in current_dict:
current_dict[parent].update({destination: {}})
mapped = True
#find if any of the top level keys match this article
if destination in destination_mapping:
current_dict[parent][destination] = destination_mapping.pop(destination)
If the parent destination name is available as a key in the current dictionary level, add the child destination as a node of the parent. The mapped status is then updated. Finally, the function searches through destination_mapping, which is the entire map, to see if the child exists as a top level node currently, and moves that top level node to the new child level node, as explained previously.
Case 2: Finding if the Child exists in the current map
Next, if the parent destination does not exist in the current map, we search the map to check if the child destination exists. As explained above, this scenario can only happen at the top level nodes, so the dictionary we are checking should match the current map, destination_mapping.
elif destination in current_dict and current_dict==destination_mapping:
current_dict[parent] = {}
current_dict[parent][destination] = current_dict.pop(destination)
mapped = True
attached = False
step_through_dict(attached, destination_mapping)
If the child destination exists, we create a new node with parent destination name as the key, pop the existing child node out and attach it to the new parent destination node. As we are adding the parent for the first time, we then need to search the entire current map to see if the parent exists somewhere else as a child node, reattaching this new parent node to the existing child node if it can be found.
For this I used another recursive function, step_through_dict, which takes not the mapped status but the attached status. Meaning whether that entire branch has been reattached. The other argument is the current dictionary it is evaluating.
def step_through_dict(attached, current_dict):
global destination_mapping, destination, parent
iter_list = current_dict.keys()
for item in iter_list:
if not attached:
if item == parent and current_dict!=destination_mapping:
current_dict[parent][destination] = destination_mapping.pop(parent)[destination]
attached = True
elif len(current_dict[item])>0:
attached = step_through_dict(attached, current_dict[item])
return attached
Given a dictionary to evaluate, the function first obtains all the keys as a list, checking through this list if the newly added parent destination exists amongst them. This will only be done if the newly added node has not yet been attached and the currently evaluated dictionary is not the top level dictionary, as in either case it would be pointless to perform any operations. If all conditions are satisfied the reattaching happens, and if it does not the function applies onto itself, this time on the next level of the dictionary.
Case 1.1
If the parent destination does not exist as a key in the current dictionary level, nor does the child destination, the function ‘map_destination’ iterates over itself and proceeds through Case 1 on the next level. This will go on until the parent is found, or until all nodes are searched.
Case 3: Neither child nor parent destination exists in current map
for destination in cleaned:
for parent in cleaned[destination]['ispartof']:
mapped = False
mapped, destination_mapping = map_destinations(mapped, destination_mapping)
if not mapped:
destination_mapping[parent] = {}
destination_mapping[parent][destination] = {}
If all nodes are searched and both parent and child destinations are not found in the existing map, map_destination terminates with value of mapped remaining at False. When that is the case we simply add a new key value pair to the map, destinations_mapping, and wait for it to be attached to the larger hierarchy when its associated destinations are added to the map.
The result
With that we’ve completed the entire mapping of the 24,924 destinations available on Wikivoyage. Time to explore the map!
The continents
Here I used the same code as I used for debugging in the earlier step. When the inconsistent spellings were not fixed there were plenty of loose ends and when they were addressed all that was level as top level nodes are continents.
with open('destination_mapping.json', 'r') as f:
destination_mapping = json.load(f)
for item in destination_mapping:
print item
You should obtain something like:
europe oceania other destinations africa south america asia north america antarctica
Regions in Asia
Next let’s see what are the node destinations under ‘Asia’:
for item in destination_mapping['asia']:
print item
There are some regions, and Mount Everest.
caucasus mount everest east asia southeast asia middle east central asia western asia south asia
Countries in Southeast Asia
Taking a look at Southeast Asia:
for item in destination_mapping['asia']['southeast asia']:
print item
We’re getting to countries finally!
east timor brunei indochina indonesia myanmar borneo philippines singapore cambodia malaysia vietnam laos thailand spratly islands paracel islands timor malaya
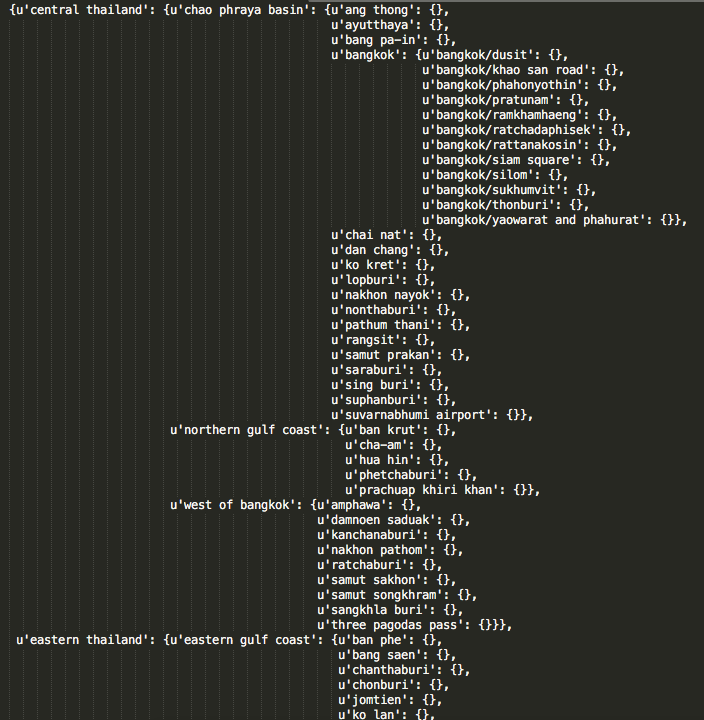
Hierarchical regional map of Thailand
And lastly let’s just take a look at the entire map under Thailand:
pprint(destination_mapping['asia']['southeast asia']['thailand']
The output is huge so here’s a snapshot.
Conclusion
And there you have it, a hierarchical map of 24,924 destinations using Wikivoyage text data. Hope you’ve found it useful. All the code (slightly edited) and some extras can be found on my Github repo here. Please let me know what you think in the comments below. Now with a more structured way of accessing the available destinations from the Wikivoyage text dump, I’m looking forward to creating more information streams/applications relating to travel from this and other public data. Stay tuned!
Pingback: Getting destination themes from Wikivoyage text - More Data